In Data Science
Unsere Partner
-
![]()
Neue Gebäudedaten: Dachformen, Flächen und Volumen
Die Datenbank CASA von infas 360 kennt jedes Gebäude in 3D. So entstehen neue Gebäudedaten über Dachformen, Dachfläche und das…
-
![]()
Baulücken in Toplagen finden
Systematische Baulücken erkennen, um anschließend das Bauland zu erschließen, könnte einen entscheidenden Schlüssel beim Wohnungsbau darstellen. Denn die Wohnungsnot und…
-
![Eine Photovoltaik-Anlage wird montiert]()
Immer mehr Neugründungen in der Solarbranche
Seit 2015 erholt sich die Solarbranche Jahr für Jahr. Immer mehr Neugründungen drängen wieder auf den Markt. Mit Wegfall der…
-
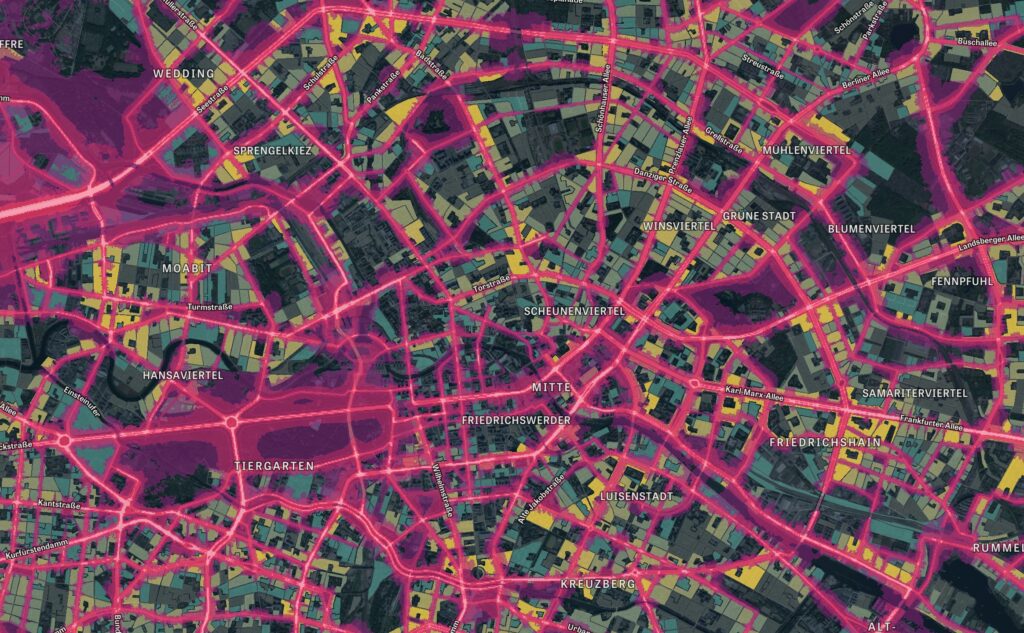
![Eine Karte von Berlin, auf der mittels Farbe die Höhe des Lärms visualisiert wird.]()
Viel Lärm, schlechte Lage?
Feinräumige Lärmdaten zeigen Umweltprobleme auf. So belastet Lärm das Herz-Kreis-Lauf System des Menschen. Auch das ist ein Grund, warum Wohnungen…
-
![]()
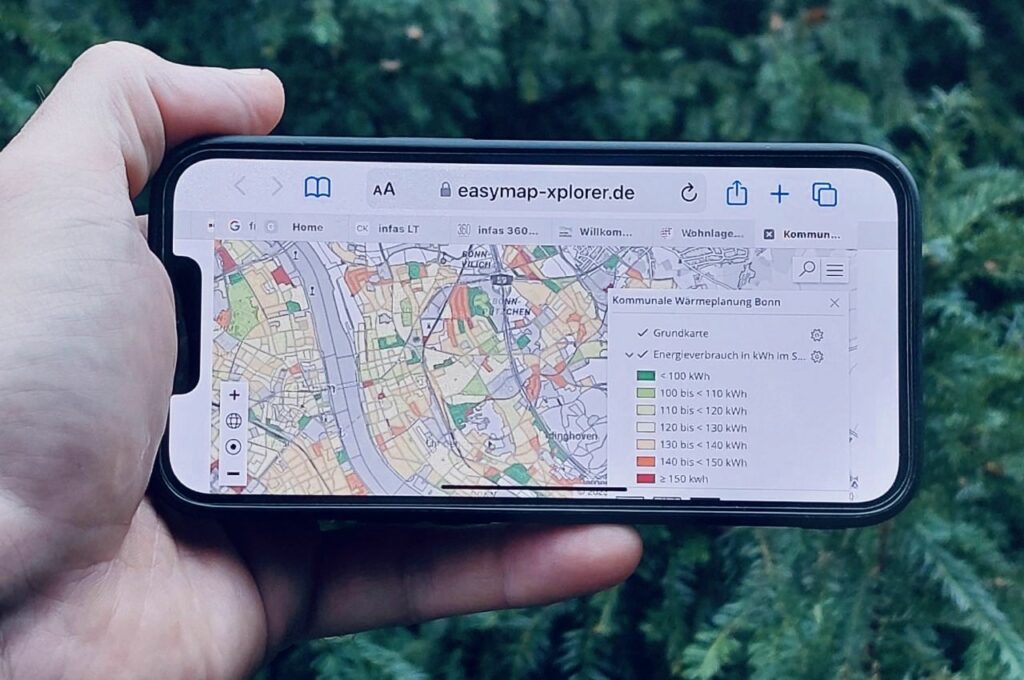
Benachbarte Hausnummern für die kommunale Wärmeplanung
Das seit 1. Januar 2024 geltende Wärmeplanungsgesetz gibt datenschutzrechtlich klare Regelungen vor. Dazu zählt auch, dass eine Datenerhebung insbesondere durch…
-
![]()
Europas ungleiche Einkommen: Kostenlosen Wandkalender bestellen – …
Europas ungleiche Einkommen nach Ländern direkt und das ganze Jahr auf einem Blick: Mit jedem kostenlosen Wandkalender 2024, der bei…
-
![]()
DSGVO-Gutachten zu Daten für die Wärmeplanung
Dürfen Stadtwerke personenbezogene Verbrauchsdaten für die kommunale Wärmeplanung nutzen? Und darf der Versorger diese Daten mit mikrogeographischen Daten kombinieren, um…
-
![]()
Neu: Klinik-Monitor zeigt Daten zu jedem Krankenhaus
Der neue Klinik-Monitor 2023 der infas 360 beinhaltet alle aktuellen Daten zu allen 2.479 Krankenhäusern in Deutschland. Dazu zählen die…
-
![]()
Feinräumige Kfz-Daten zeigen schwierigen Wachstumsmarkt E-Auto
Geht es nach der Politik, sollen 2030 bundesweit 15 Mio. E-Autos zugelassen sein. Bisher sind es nur ein Bruchteil davon… -
![]()
Data Science und easy Mapping aus einer Hand
Wir informieren heute darüber, dass die infas LT GmbH mit Eintragung im Handelsregister am 25.10.2023 auf die infas 360 GmbH…